Apr 10, 2024
Deep Learning - Optimization of the Training Dataset Construction Process
Deep learning projects face multiple challenges, including the high cost of generating large-scale labeled datasets, debugging them, and their impact on the obtained results. The choice of which data to use, which ones to label, and how they affect these models has a significant impact on the economic and computational viability of projects. Therefore, it is crucial to choose what tools and techniques to use during the process of creating these datasets in various domains such as computer vision, natural language processing, etc.

AI algorithms learn a reality represented by the data used for their training and make decisions based on it. Therefore, if the data are not of good quality or do not represent the entire domain in which one wants to work, the system will not learn correctly and will fail. Therefore, having a good dataset is vital to the success of our solution.
One of the essential tasks that require a significant amount of time in AI-related projects is the classification and labeling of data. Manual labeling, although the most accurate since no algorithm can currently compare to the human eye, is the most costly in terms of time and human effort, two generally valuable and limited resources. Seeing this problem, I started researching what tools or strategies could address this issue. After reading many books and academic articles that provided me with techniques to tackle the problem, I implemented a system using the classification strategy called "Human-in-the-Loop", where data labeling is a task performed in cooperation between the system and humans but using techniques to minimize human intervention and thus reducing the cost of building a dataset.

Juan Ignacio
Senior Software Engineer
Table of Contents
How does the Human-in-the-Loop strategy work in dataset construction?Strategic Data Selection for Manual LabelingImplementationConclusion4 minutes read
Have a project?
How does the Human-in-the-Loop strategy work in dataset construction?
The "Human-in-the-Loop" strategy in dataset construction involves the active participation of people in the process of creating and improving the dataset. This includes tasks such as manually annotating information and resolving discrepancies or ambiguities. The idea is for humans to contribute their expertise and judgment where automatic algorithms may fail or be insufficient, thus ensuring the quality and relevance of the dataset for use in training artificial intelligence models.
The collaboration between humans and automated systems is often iterative, starting from an initial classification of the data by the model (usually pre-trained) and presenting some data to humans for manual labeling. These labeled data will become part of the model's training set in the next iteration step, where a new classification will be made. This mechanism allows for continuous improvement of the accuracy and utility of the dataset.
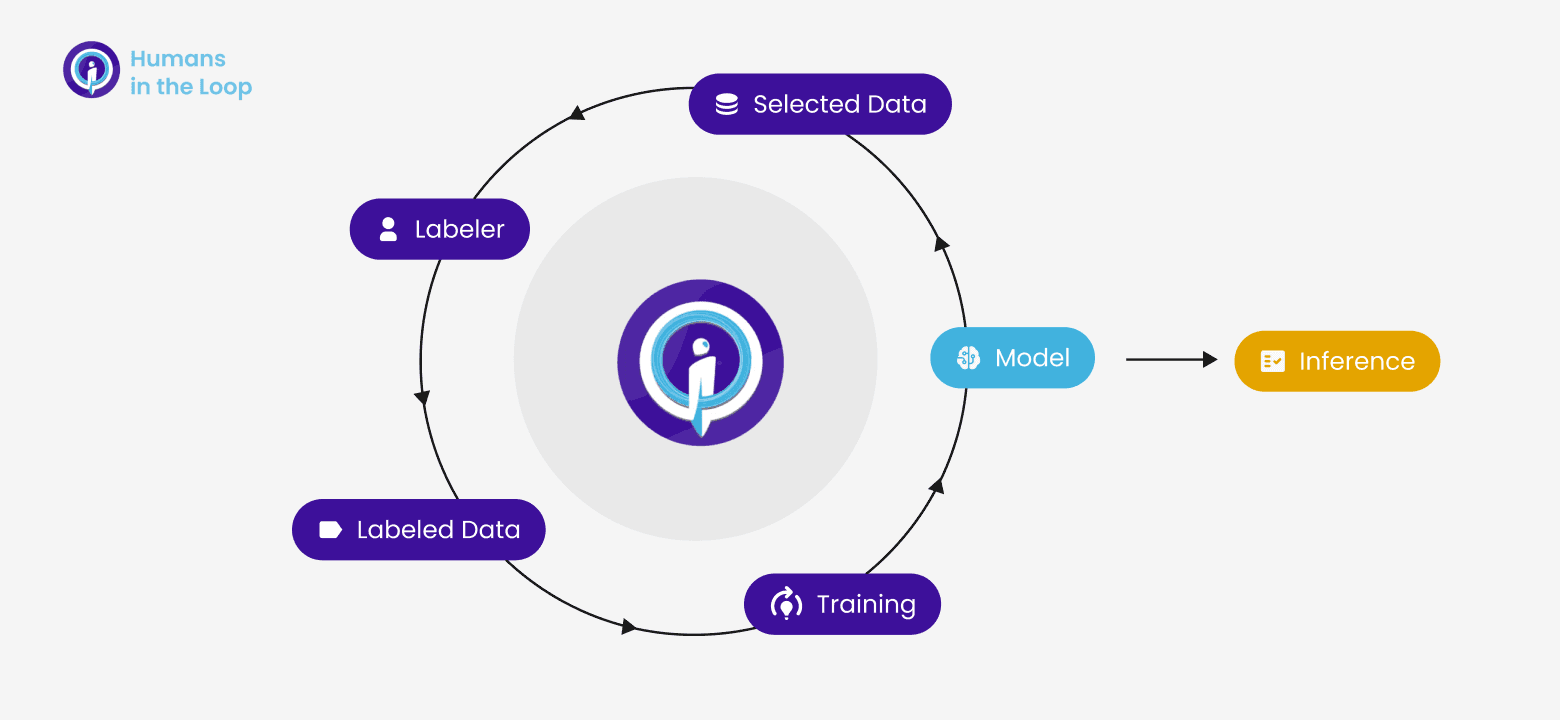
Strategic Data Selection for Manual Labeling
There are several strategies for selecting data for manual labeling in a system that utilizes the "Human-in-the-Loop" strategy. The simplest one is to randomly select a dataset and present it for manual labeling to obtain a percentage of data that we know are well labeled. The issue arises when we have a dataset to label where a significant portion of them have similar characteristics, as there is a high probability of selecting data that do not provide new information to our model. This way, we are wasting a very important resource, which is human labeling in the learning cycle. The key point is to intelligently select the data to help the model achieve more accurate classification, thus increasing precision and reducing human intervention since there will be fewer iteration steps to achieve satisfactory classification.
There are two sampling principles that help in strategically selecting data:
Uncertainty Sampling:
As the name suggests, uncertainty sampling is a strategy that involves selecting a set of unlabeled elements taken from a region of the feature space where the model is unsure how to classify them. As shown in Figure 2, these are the elements closest to the decision boundary.

Diversity Sampling:
Often, data bias arises from the overrepresentation of certain types of data. For instance, if we consider classifying images of different animal species and there are many images of one species but few of another because the photos were taken in a region where the latter species is less common, the model will learn a lot about the overrepresented species and little about the others.
Diversity sampling addresses the issue of data that the algorithm is not familiar with, scarce data, or data that occurs less frequently but is crucial in many problems to balance the data the algorithm is trained on and gains knowledge from.

The correct labeling of these data will help the model accurately predict the label of data with similar characteristics in the next iteration.
Both strategies are combined to achieve sampling where the model has higher uncertainty that is also diverse (data unknown to the model in its current state).
Implementation
By combining the concepts of "Human-in-the-Loop" with the combined uncertainty and diversity sampling strategies, I have implemented a system that has successfully constructed datasets with high performance efficiently (in a few iteration steps), thus reducing the cost of dataset generation.
To have a performance comparison point for our system, I implemented a system that uses the "Human-in-the-Loop" strategy with random data selection for manual labeling. Both algorithms were run several times with the same datasets, and the average accuracy and F-measure were plotted, yielding the results shown in Figures 4 and 5.
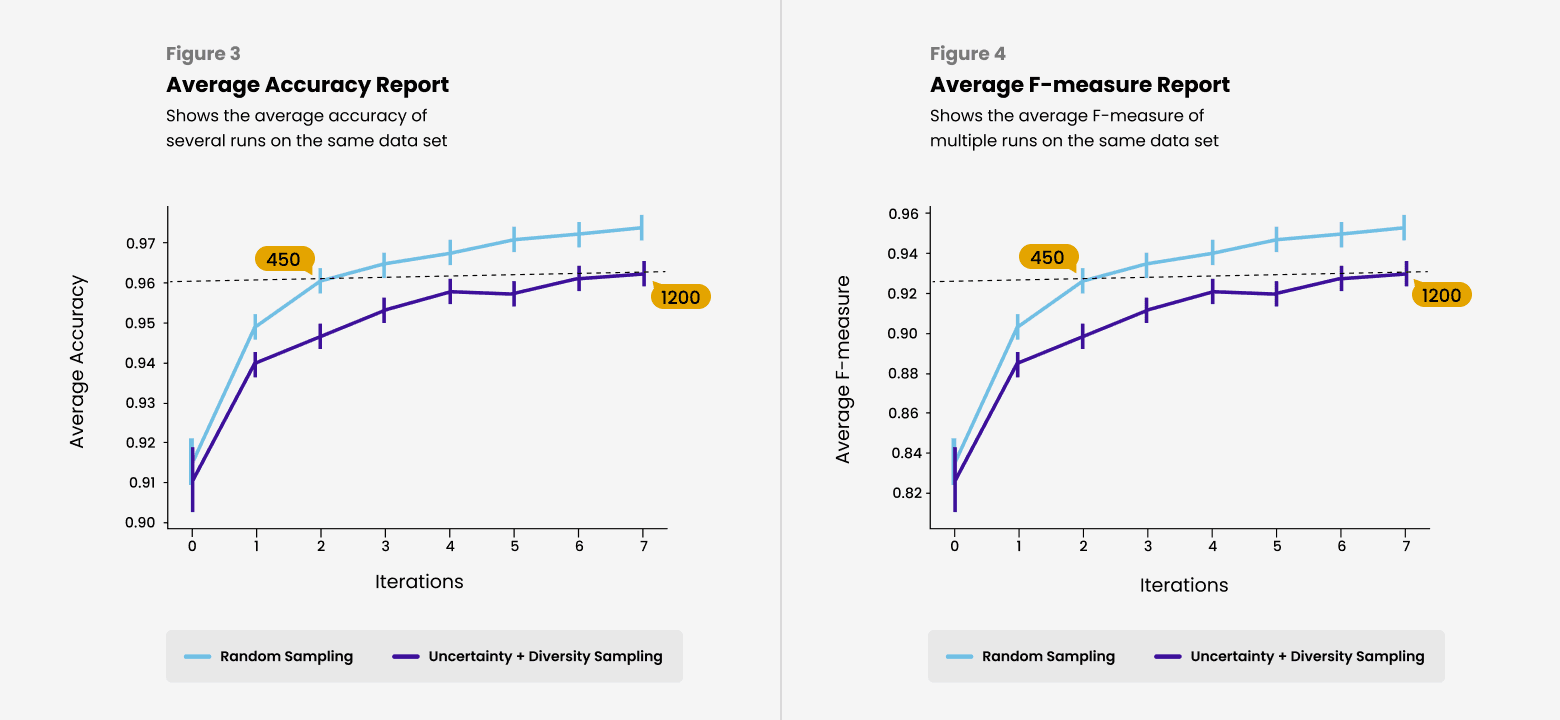
Figure 4 shows that by labeling only 450 data points presented by our system for manual labeling, we achieve the same accuracy as labeling 1200 randomly selected data points, implying a reduction in dataset generation effort. A similar result is shown in Figure 5, which plots the average F-measure.
Conclusion
When facing a deep learning problem, we generally think about designing algorithms or models to solve it with the premise that the data are already given, that's what we have to work with, and we must improve and adjust the model based on them. This paradigm has changed in recent years, proposing to give more prominence to the data, improving their quality so that not only the model adjusts to the data, but also the data adjusts to the model.
Constructing a dataset with the right size, data quality, and correct labeling is a major challenge that AI-related projects must face, where the cost in terms of time and money is often high and can affect its viability.
Seeing this issue and after extensive research, reading various books and academic articles that provided me with tools and techniques to address the issue, I implemented a system using the "Human-in-the-Loop" strategy with strategic selection of a small amount of data for manual labeling, significantly reducing human intervention and therefore the cost of building a dataset.